
IDEAS recruits excellent PhD candidates at the interface of data science and environmental & life sciences. The recruitment process is project-based and designed to create a strong match between your profile, your preferred topic, and the supervision team.






Employment & funding
All IDEAS PhD positions are fully funded (100%) according to TVöD E13 for 3 years with the possibility of 1 year extension.
Key dates & timeline
Application window
29.06.2026 - 26.07.2026, 23:59 CEST
Candidate ranking
until 21.08.2026 (excellence-based ranking)
Interview week
24.08.2026 - 04.09.2026 (online interviews)
Expected start date
01.01.2027
Dates may be adjusted slightly. Shortlisted candidates will be contacted by email.
More topics than positions
IDEAS typically offers a pool of project topics that is larger than the number of available positions, enabling better matching between candidates and projects.
In the second call, we advertise 4 funded PhD positions across 5 project topics. This means that even strong candidates may not receive an offer for their first-choice topic if it is already filled—however, the process is designed to support fair matching across multiple topics.
Candidates are evaluated and ranked based on scientific potential, achievements, and fit with the school and projects. More information about the process here
Innovation Track (propose your own idea)
In addition to the advertised projects, IDEAS offers an Innovation Track for exceptional, self-developed project ideas. A limited number of positions may be reserved for such proposals, which are considered alongside standard applications.
Your idea can be shaped freely, but it must fall within Life Sciences & Health or Environmental Sciences. Before applying, you must contact two Partner PIs from the PI list and obtain their support: one PI from a Helmholtz Center and one PI from a university (Y-supervision principle).
Write your project proposal (max 2 pages) and add it to your cover letter. Then proceed with the application process as detailed below.
PhD projects

FloodLens
Seasonal and sub-seasonal forecasting of spatially co-occurring floods
Supervising PIs:
Dr. Larisa Tarasova (UFZ) & Jun.-Prof. Dr. Marlene Kretschmer (Leipzig University)
Additional PIs:
Prof. Dr. Marina Höhne (Leibniz Institute for Agricultural Engineering and Bioeconomy, University of Potsdam)
Keywords: flood forecast, S2S, extreme events, causality
Project description:
Severe storms and floods often cause large damages to society, and their frequency and intensity are expected to increase with climate change. When such extremes occur simultaneously over different regions, emergency response and relief are strained. Skillful sub-seasonal to seasonal (S2S) forecasts of spatially co-occurring extremes are urgently needed to improve the defense and emergency relief preparation of such events, yet, physical models struggle to provide reliable forecasts on this decision-relevant timescale. Advances in deep learning (DL), particularly attention-based models offer promising avenues for improvement. However, the black-box nature of these models limits their usability in high impact environmental decision-making, where robustness, physical consistency, and trustworthiness are essential. In particular, DL models are prone to learning spurious correlations and dataset-specific biases, especially under limited observations and non-stationary climate conditions. This project will therefore combine advanced deep learning architectures and causal representation learning frameworks coupled with explainable AI (XAI) to develop physically interpretable, robust, and trustworthy data-driven forecasts of spatially co-occurring flood events and their large-scale atmospheric precursors.
This project will address the following questions: How to map large-scale atmospheric circulation patterns to regional flood hazard? How to constrain powerful but data-dependent DL models using guided (pre-)training and regional learning? How to ensure that the dynamics learned are causally meaningful?
In this project we will develop DL-based S2S framework for forecasting spatially co-occurring floods that combines predictive skill with physical interpretability and uncertainty quantification. Beyond improving forecasts of widespread flood events, detecting changes in frequency of their dynamic precursors within future projections can offer insights into evolving spatial flood risks under climate change.
Disciplines: hydrology, climate sciences, forecasting, machine learning
Work environment:
You will be working with the interdisciplinary groups of hydrologists, climate and machine learning scientists. You will have access to word-class IT infrastructure of UFZ and Helmholtz Association. You will be supported by three advisors that offer leading expertise in flood generation processes, climate causality and explainable Artificial Intelligence. You will have the opportunity to work in an international and vibrant environments of UFZ and Leipzig University.
Degree:
You will have the possibility to obtain a PhD degree from Leipzig University (Faculty for Physics and Earth System Sciences).
Prerequisites:
To conduct this research, you should
- hold a very good university degree (MSc or an equivalent) in meteorology, hydrology, climate science, Data Science, computer science, mathematics, physics or related disciplines.
- have excellent programming skills
- strong scientific rigor a strong interest to work in a highly interdisciplinary environment.

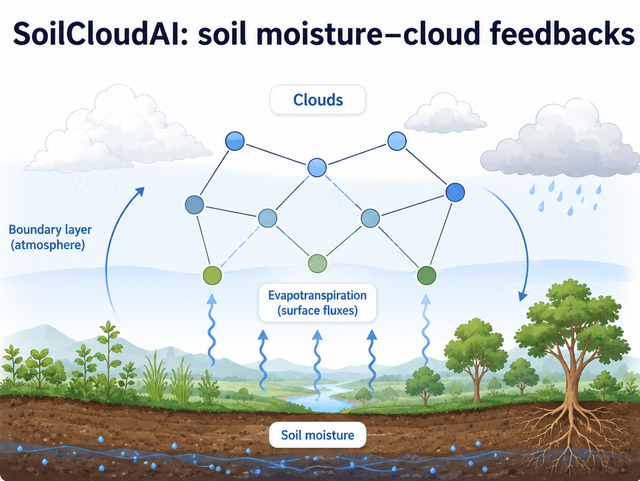
SoilCloudAI
Interpretable and probabilistic AI for land–atmosphere feedbacks during hydroclimatic extremes
Supervising PIs:
Prof. Dr. Jian Peng (UFZ) & Prof. Dr. Johannes Quaas (Leipzig University / ScaDS.AI)
Additional PI / third supervisor:
Dr. Josefine Umlauft (Leipzig University / ScaDS.AI)
Keywords: soil moisture–cloud feedbacks, land–atmosphere coupling, hydroclimatic extremes, graph-based AI, uncertainty quantification, Earth observation
Project description:
Soil moisture–cloud feedbacks can influence the development and persistence of droughts, heatwaves, and other hydroclimatic extremes. Yet these feedbacks remain difficult to quantify because they depend on nonlinear interactions between soil moisture, evapotranspiration, surface fluxes, boundary-layer conditions, cloud formation, and regional moisture transport, and because they vary across water-limited, transitional, and energy-limited regimes.
This PhD project will investigate soil moisture–cloud feedbacks using in-situ observations, satellite products, reanalysis datasets, and Earth system model simulations. The candidate will develop and apply interpretable and probabilistic graph-based AI methods to represent land–atmosphere interactions as evolving spatial networks, identify feedback pathways, and quantify uncertainty in inferred relationships. The project will focus particularly on droughts and heatwaves, where soil moisture–cloud feedbacks may reorganize and amplify hydroclimatic extremes.
The candidate will be mainly based at UFZ and closely connected to ScaDS.AI and Leipzig University. The project offers an interdisciplinary environment at the interface of Earth system science and data science, with access to large environmental datasets, high-performance computing infrastructure, methodological training, and expertise in land–atmosphere interactions, cloud–climate processes, machine learning, and uncertainty quantification.
Disciplines: Earth system science, atmospheric science, remote sensing, data science
Work Environment:
You will join an interdisciplinary research environment spanning UFZ, ScaDS.AI, and Leipzig University. At UFZ, you will be embedded in a collaborative group with strong expertise in land-atmosphere interactions, remote sensing, hydroclimatic extremes, and computational Earth system science — an international and supportive team with regular scientific exchange and mentoring.
The project offers excellent working conditions at the interface of Earth system and data science, including access to high-performance computing infrastructure, established geospatial data-processing workflows, and large environmental datasets. Through ScaDS.AI, you will be connected to a lively data-science community with seminars, methodological training, and expertise in machine learning, statistical learning, and uncertainty quantification.
Degree:
The candidate will have the possibility to obtain a PhD degree from Leipzig University.
Required qualifications:
To conduct this research, applicants should:
- hold a MSc degree in data science, computer science, applied mathematics, environmental sciences, atmospheric sciences, geosciences, physics, hydrology, or a related field.
- have good programming skills
- have a strong interest in working at the interface of Earth system science and data science.

TRACE-GBM
AI-guided design of mini-protein radiotracers for glioblastoma imaging and theranostics
Supervising PIs:
Prof. Dr. Clara T. Schoeder (Leipzig University, Institute for Drug Discovery; ScaDS.AI Dresden/Leipzig) & Prof. Dr. Andreas Maurer (HZDR; Leipzig University)
Keywords: Protein Design, RFdiffusion, ProteinMPNN, Active Learning, Glioblastoma, EGFRvIII, PET Imaging, Radiotheranostics
Project description:
Glioblastoma remains one of the deadliest human cancers, with limited options for precise molecular imaging and targeted therapy. EGFRvIII is a tumor-specific biomarker expressed in a subset of glioblastomas and represents an attractive target for precision diagnostics and radiotheranostic applications. However, current targeting approaches mainly rely on antibodies or conventionally discovered peptides, which often show suboptimal pharmacokinetics for molecular imaging. In addition, the heterogeneous expression of EGFRvIII requires new strategies that enable robust and specific tumor recognition.
Recent advances in generative artificial intelligence, including RFdiffusion, ProteinMPNN, and modern protein structure prediction methods, provide unprecedented opportunities to design target-specific binding proteins de novo. These mini-proteins combine favorable biochemical properties with excellent potential for radiopharmaceutical development, yet AI-designed binders have rarely been optimized through iterative experimental validation for in vivo imaging applications.
This project aims to establish a data-driven design-build-test-learn framework for the development of next-generation radiotheranostic proteins. Computationally designed mini-protein binders will be generated using state-of-the-art AI methods and continuously improved through active learning by integrating experimental data on binding affinity, protein stability, expression, radiolabeling, and molecular imaging performance. Selected candidates will be translated into copper-64-labelled PET radiotracers and evaluated in preclinical glioblastoma models.
The project addresses four key questions: Can AI generate high-affinity binders suitable for molecular imaging? Can experimental feedback improve computational protein design through active learning? Which molecular properties determine successful translation into PET radiotracers? And can AI-designed mini-proteins enable specific visualization of glioblastoma in vivo?
Beyond developing novel radiotracers for brain tumors, the project will establish a broadly applicable framework that connects generative AI, protein engineering, and molecular imaging to accelerate the development of future radiotheranostic agents.
Disciplines: Computational Biology, Protein Engineering, Machine Learning, Radiopharmaceutical Sciences, Neuro-Oncology
Work Environment:
You will be a member of two highly interdisciplinary research groups at Leipzig University and the Helmholtz-Zentrum Dresden-Rossendorf (HZDR). The project combines internationally recognized expertise in computational protein design, machine learning, radiopharmaceutical development, molecular imaging, and neuro-oncology. You will have access to high-performance computing infrastructure through ScaDS.AI, protein engineering and yeast-display facilities, radiochemistry laboratories, and state-of-the-art preclinical PET imaging systems. The two laboratories are located within cycling distance in Leipzig, enabling close interaction with researchers from both groups and providing training across the complete translational pipeline from AI-driven molecular design to in vivo validation.
Degree:
You will have the possibility to obtain a PhD degree from Leipzig University.
Prerequisites:
To conduct this research, you should
- hold a very good university degree (MSc or equivalent) in Bioinformatics, Computational Biology, Biotechnology, Biochemistry, Structural Biology, Molecular Biology, Biomedical Engineering, Data Science, or a related discipline.
- have experience in programming (e.g. Python), machine learning, quantitative data analysis, protein modelling, or molecular biology techniques.
- be highly motivated to work at the interface of computational and experimental research.
- have a strong interest in artificial intelligence, protein engineering, molecular imaging, and translational cancer research.

SafeBEEP
Safeguarding Bees by Predicting Biotransformation of Pesticides
Supervising PIs:
Prof. Dr. Martin von Bergen (UFZ) & Prof. Dr. Peter F. Stadler (Leipzig University)
Keywords: Microbiome-Host Interactions, Side Effects of Plant-Protection Products on Bees, Prediction of Microbial Degradation, LLM, and Graph Representation of Chemical Reactions
Project description:
The sucessful candidate will improve the ai-based prediction of microbial biotransformation of toxic plant protection products by the microbiome of honey bees. For the relevant pesticides the chemical basis of reactions will be analysed by graph representation of chemical reactions. The aim is to identify microbial reactions that will enable to reduce the unintended negative effects in honey bees and allow for an improved design of pesticides in the future.
The successful candidate will work in Leipzig at both the UFZ, in the MOLTOX Department headed by Martin von Bergen, and the Interdisciplinary Centre for Bioinformatics in the group of Peter Stadler allowing them to use the resources and expertise available at both institutions. We offer a well structured and supportive supervision, a very friendly work environment in both groups, and excellent technical resources at both institutions. Above all, we believe that working on AI-based approaches to address the urgent biodiversity crisis is a meaningful motivation. We expect advanced knowledge in data science and machine learning, at least an intermediate understanding of chemistry and biochemistry, and a strong interest in interdisciplinary work and environmental health. The professional background is less relevant than the actual skills and can be in Chemistry, Informatics, or Mathmatics.
Disciplines: Molecular Toxicology, Microbiome-host interactions, Microbial Degradation of Xenobiotics,
Computer Science, Chemistry, Bioinformatics, Discrete Mathematics, Data Science
Work environment:
You will work in an interdisciplinary, international team spanning UFZ and Leipzig University. At UFZ, you will join the Department of Molecular Toxicology (Prof. von Bergen), embedded in a lively group of environmentally enthusiastic colleagues with ties to Helmholtz-wide data science initiatives and ongoing research on microbiome-host interactions. At Leipzig University, you will be part of Prof. Stadler's Bioinformatics group, with strong expertise in algorithmic bioinformatics, cheminformatics, and graph theory. Through Prof. Stadler's roles at ScaDS.AI and the Zuse School for Embedded and Composite AI (SECAI), you will be directly connected to a thriving community of AI researchers.
Both locations offer excellent computing resources, including dedicated bioinformatics infrastructure at Leipzig University and high-performance computing facilities at UFZ.
Your supervision team brings complementary expertise in graph theory, AI/machine learning, and computational toxicology, backed by a wider network spanning biodiversity research and Helmholtz AI. You can look forward to a friendly, collegial atmosphere with regular seminars, joint group meetings, and opportunities to present your work at internal and external events.
Degree:
You will have the possibility to obtain a PhD degree in Computer Science from the Faculty of Mathematics and Computer Science at Leipzig University.
Prerequisites:
To conduct this research, you should
- hold a very good university degree (MSc or equivalent) in Computer Science, Bioinformatics, (Computational) Chemistry, Mathematics or a closely related discipline.
- For candidates from Computer Science, Mathematics or related fields, a strong interest in the natural sciences (chemistry, toxicology, environmental/life sciences) is expected.
- For candidates with an MSc in Chemistry, Molecular Biology or related fields, a strong interest in computational methods and their formal foundations (algorithms, statistics, machine learning) is required.
- In all cases, solid programming skills (preferably in Python) and familiarity with basic concepts in machine learning/data science are desirable.
- Prior experience with graph-based methods, cheminformatics or predictive modeling is an advantage but not a strict requirement, provided there is a clear motivation to develop these skills during the PhD.

DigitHealth
Towards Digital Markers of Tissue Health Through Continuous Metabolic Sensing
Supervising PIs:
Prof. Dr. Larysa Baraban (HZDR) & Jun.-Prof. Dr. Julia Westermayr (Leipzig University)
Keywords: lab on chip, smart biomarkers monitoring, digital biomarkers, machine learning
Project descripition:
This PhD project aims to develop novel digital markers of tissue health from continuous metabolic sensing data, combining advanced biosensing technologies with machine learning and data science. The research follows a structured workflow: Generate Data → Expand Biological Measurements → Learn Digital Markers → Predict Outcomes and Support Decisions.
Your tasks
Validation of Continuous Metabolic Monitoring
You will establish and validate a platform for continuous monitoring of tissue metabolism using microfluidic sensing and microdialysis technologies. Existing and newly acquired lactate datasets will provide the foundation for subsequent computational analyses.
Multimodal Tissue Physiology Monitoring
You will expand the sensing platform to additional metabolic and physiological parameters, including glucose, pyruvate, glycerol, pH, oxygenation, and inflammatory markers — creating an integrated multimodal dataset for a more comprehensive characterisation of tissue health.
Digital Marker Discovery
You will develop machine learning and time-series analysis methods to identify physiologically meaningful temporal patterns in continuous metabolic measurements, discovering digital markers that capture tissue states and adaptations beyond conventional concentration-based biomarkers.
Predictive Modeling and Decision Support
You will develop predictive models for physiological state estimation, early-warning detection, and multimodal data integration — exploring whether continuous metabolic monitoring can enable earlier detection of tissue dysfunction and support future precision-monitoring applications.
By the end of the project, you will have contributed to novel methods at the intersection of biosensing, machine learning, and digital health.
Disciplines: Microsystems engineering, Biosensors, Data Science
Work environment:
You will be working with the international dynamic team, consisting of engineers, biologists and develop strong cooperation to the clinical scientists thanks to the cooperations at University Clinic Dresden. Because we welcome candidates with either a medical/life-science or a computational/data-science background, we offer the flexibility to choose the degree-awarding institution that best fits the candidate's career track.
Degree:
You can choose to be awarded the PhD degree either by the Medical Faculty of the Dresden University of Technology or by the mathematical/informatics/chemistry faculty at Leipzig University.
Prerequisites:
For a project at the interface of continuous biosensing, physiology, and data science, we search for a candidate with a Master's degree in Biomedical Engineering, Biotechnology, Life Sciences, Bioengineering, Medical Technology, Physiology, or a related field. You should also have a strong interest in translational biomedical research and physiological monitoring. Required skills:
- Experience with experimental laboratory work
- Knowledge of physiology, metabolism, tissue perfusion, or biomarker research
- Experience with sensor technologies, microfluidics, microdialysis, or biomedical instrumentation is advantageous
- Ability to design, conduct, and document experiments
- Strong programming and data analysis skills (Python, R, or MATLAB)

Innovation Track
You have an own project idea fitting within IDEAS' scope?
If you have an own project idea for a PhD project at the intersection of Domain and Data Science, that falls within Life Sciences & Health or Environmental Sciences, you write a short project proposal and contact 2 Partner PIs from our PI list who could support you based on our Y-supervision principle and obtain their support.
Then you submit your application and get evaluated together with all other applicants based on your scientific potential, achievements, and fit with the school.
Prerequisites
You should have
- A strong MSc (or equivalent) in computer science, data science, or a field related to your chosen project.
- Solid programming skills and experience with machine-learning methods.
- Very good written and spoken English skills for work in an international research environment.
How the application process works
Select and rank projects you're interested in
Review the PhD projects listed above and select up to three projects you would seriously consider. Then rank your selected projects (1 = top choice). You must choose at least one project — or choose the Innovation Track to submit your own project idea (see details above).Provide all required information
Use the application package builder below, a mask to enter all required information is provided there.Prepare your documents
- Cover letter explaining your motivation to pursue a PhD within IDEAS, your research interests, and relevant experience and, in case you chose to submit your own project idea, add this to the cover letter
- CV
- Master's certificate (digital copy)
- Transcript of records
- Two reference letters (if you do not have reference letters, provide at least the contact details for 2 people who would give you a reference if contacted)
- Create one PDF
Combine the documents above in this order into one single PDF.
Use the application package builder to compile your materials and provide all the relevant information for your application. You can upload your PDFs here, and rank your preferred PhD projects directly on this page (the ranking is done locally in your browser—no files are required for that step). The tool generates one merged PDF you can download. Then proceed to the recruiting page to enter your personal details and upload your application package. We strongly recommend to use this tool, as we are only able to consider applications that provide all the required materials and information.
5. Submit
Submit your compiled application package via the UFZ recruiting page.
For more information contact our coordinators

Dr. Sandra Hille
Coordinator IDEAS (UFZ)
Contact

Anne Pidt
Coordinator IDEAS (HZDR)
Contact